

吞吐提升76%!小红书开源RL训练引擎Relax
吞吐提升76%!小红书开源RL训练引擎Relax小红书AI平台团队刚刚开源了Relax——一个为全模态数据、Agentic工作流和大规模异步训练协同设计的现代RL训练引擎!实测全异步Off-Policy模式相比共卡On-Policy吞吐提升76%,相比veRL的全异步实现提升20%!
来自主题: AI技术研报
5795 点击 2026-04-15 09:23
小红书AI平台团队刚刚开源了Relax——一个为全模态数据、Agentic工作流和大规模异步训练协同设计的现代RL训练引擎!实测全异步Off-Policy模式相比共卡On-Policy吞吐提升76%,相比veRL的全异步实现提升20%!

提起马卡龙,你会想到什么?是橱窗里的精致甜点,一种“少女心”的味觉象征?还是代表了温柔优雅的时尚配色?当一个AI产品也被命名为“马卡龙”,这份联想便悄然发生了偏移:从舌尖的甜,转向科技的未知,却又奇妙地保留了那一份色彩与气质。
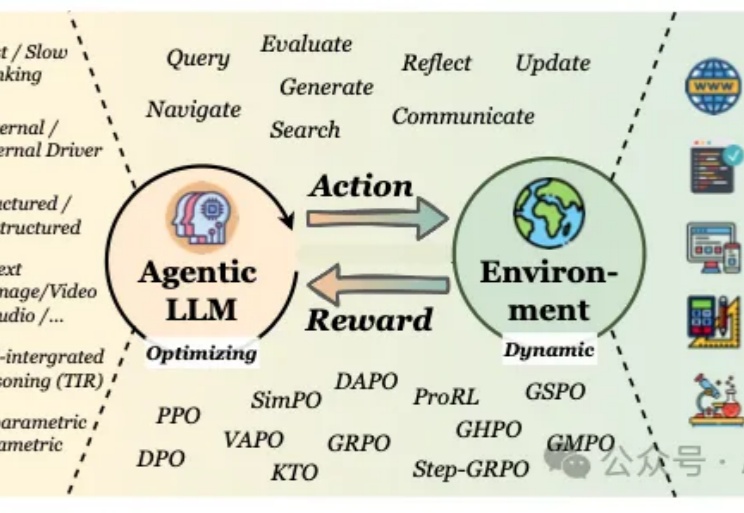
当我们谈论大型语言模型(LLM)的"强化学习"(RL)时,我们在谈论什么?从去年至今,RL可以说是当前AI领域最炙手可热的词汇。

来自牛津大学、新加坡国立大学、伊利诺伊大学厄巴纳-香槟分校,伦敦大学学院、帝国理工学院、上海人工智能实验室等等全球 16 家顶尖研究机构的学者,共同撰写并发布了长达百页的综述:《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。